Blockchain Byte - Week 12 : Hashing

Table of Contents
- Recap
- Cryptography
- Function
- Hash Function
- Hash Table
Recap
Last time we introduced nodes and their core functions in a blockchain. Some of their core functions are :
- Take transactions pending for processing
- Check their integrity &
- Record them on the ledger.
- Being a point of communication in the Blockchain network (Network routing function).
We then classified nodes into :
- Full Nodes
- Light Nodes
Today we will introduce another concept called hashing. Before we get into hashing, let us dial back to Week 3 where we introduced the term Cryptography.
Cryptography
Cryptography is a technique of securing communication through use of codes so that only the person for whom the information is intended can access it and use it. This prevents unauthorized access.
Cryptography is made possible through Encryption which is the process by which data is scrambled so that only the authorized parties can understand the relevant information and no one else.
In technical terms, it is the process of converting human-readable plaintext to incomprehensible text, known as cipher text. Only the intended recipient of the communication can decipher the cipher text. The process of conversion of cipher text to plain text is known as Decryption.
Below diagram is a simple representation of encryption & decryption:
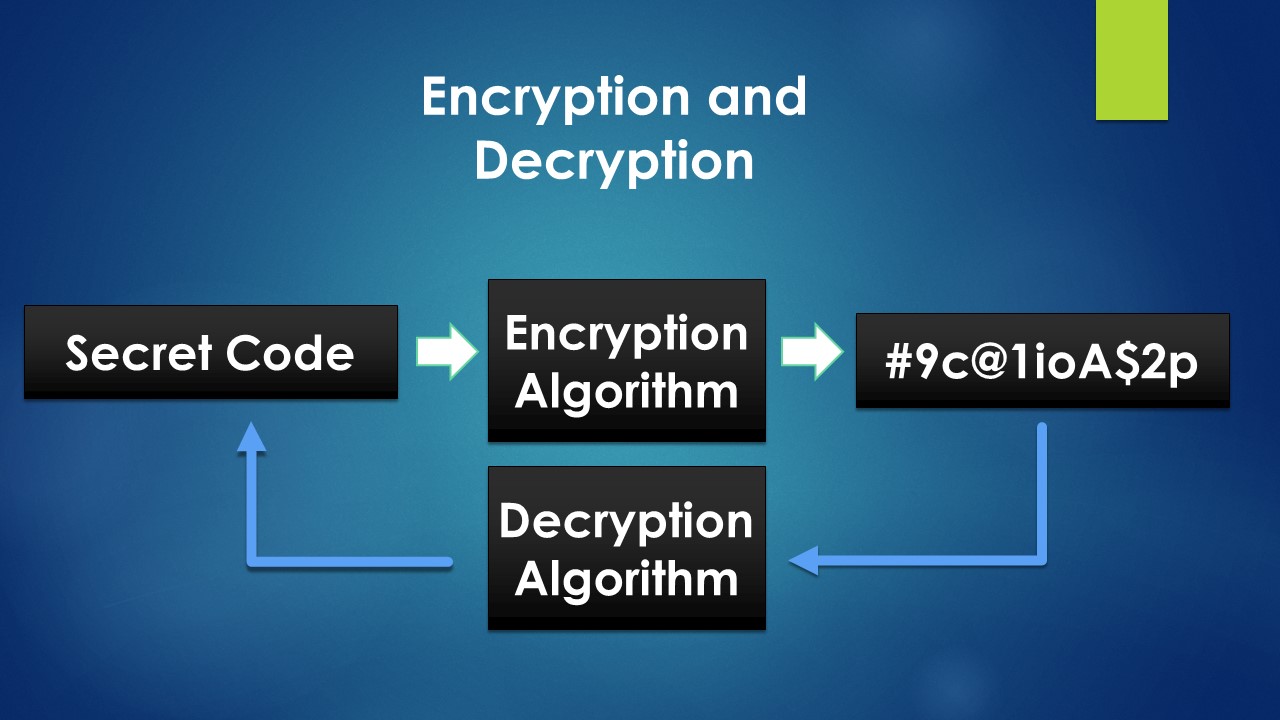
Now, let us take this one step further. Imagine we have a message which needs to be encrypted and sent to someone. We use an encryption algorithm and get a cipher text. If we use the same message, we get the same cipher text all the time.
But if we change even one letter in the message, we get an entirely different cipher text. The below diagram makes it more clear
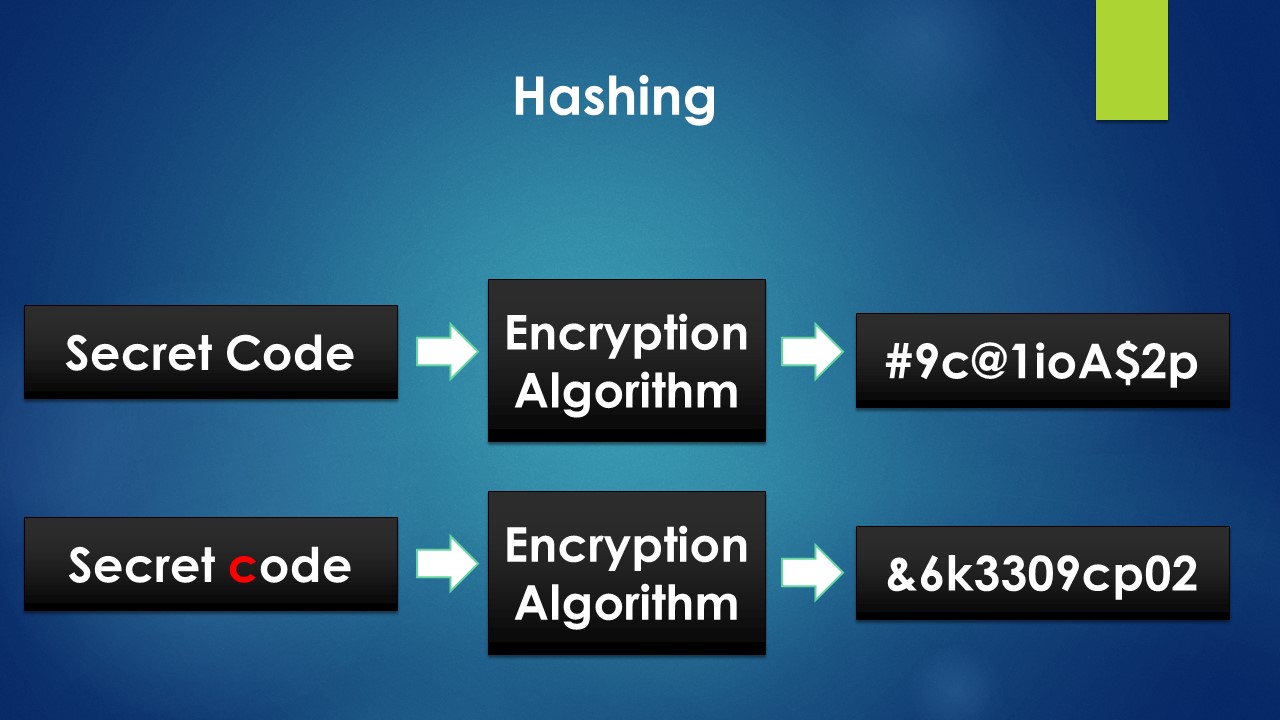
The capital "C" in code was modified to to small "c" and that changed the entire output. Thus an output is specific only to a particular input. Even if a small change is made to the input, the output changes completely.
Let us take this one step further - what if we are able to generate an output of fixed length irrespective of the length of the input? - Meaning, if the input contains 10 characters, 100 characters or 1000 characters, the output will contain only 10 characters which is of fixed length. This is called Hashing & is done through a Hash Function. Before we explain hash function, let us understand what is a Function in programming.
Function
Generally, a computer program contains instructions on how a software should behave depending on how a user interacts with it. Big software programs have millions of lines of code. A user can do the same action at various points in time. or example, in any online market place like Amazon etc., if a user clicks "Add to cart", the item is added to his / her cart. There can be different scenarios when a user clicks "Add to Cart" like
- Immediately after logging in
- After reviewing the item
- After reviewing multiple items etc.,
It doesn't make sense to repeat the code for "Add to Cart" under each scenario which will make it longer & complicated.
Hence, to make the program compact & easier, this part is written in one particular section which is used ("called") at various points in the program instead of writing this code multiple times. This particular section is called a function. This prevents repetition of the same code in different parts of the program. In other words,

Hash Function
So, a function does something in a program. It does some action when called.
As per Wikipedia, a hash function is any function that can be used to map data of arbitrary size to fixed-size values.
The output returned by a hash function are called hash values, hash codes, digests or simply hashes. (which is the output on the right hand side of our hashing visual above).
To put it simply, hashing is the process of having an input of any length but getting an output of a fixed length.
This means the output is independent of the length of the input.
With that being clear, how is this output generated? The hashing algorithm is a mathematical formula which takes an input and hashes it to the output. E.g., : in a SHA - 256 (Secure Hashing Algorithm - 256), irrespective of the size of the input, the output will always be a fixed 256-bits length.
Why is this important? Using fixed length hashes to access information instead of the data itself makes it faster & easier to access the information in a database.
In week 3, we touched upon databases (an organized collection of structured information or data, typically stored electronically in a computer system).
What do we do with a database? Mostly
- We get information from the database for analysis (Data retrieval) &
- It is a place of storing information (Storage).
Data retrieval and storage are critical parameters of any software program. Any program should have efficient data retrieval logic & storage mechanisms.
Hash functions and their associated hash tables are used in data storage and retrieval applications to access data more efficiently. They require an amount of storage space only fractionally greater than the total space required for the data or records themselves. Hashing is a computationally and storage space-efficient form of data access. (Source : Wikipedia). We will explore this in the coming weeks.
What is a hash table?
Hash Table
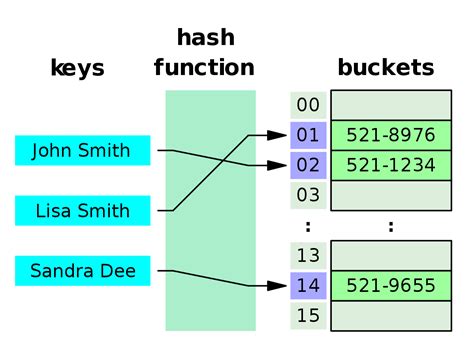
A hash table is a data structure that can map keys to values. A hash table uses hash functions to generate keys or index. Hence each data item has its own unique index value. Access of data becomes very fast and easy if we know the index of the required item. Where is this used?

When we try to access a name from our contact list, a hash function allocates an index or key to each name that enables faster access when you type in the name. Otherwise, the application has to go over each and every contact in the list from beginning till it reaches the relevant name which could take longer time and is an inefficient way to search data. The below diagram from Wikipedia makes it more clear.
Normally databases store data & makes it easier for us to access them. A blockchain also stores data. But it uses hash functions in order to create a record of the data recorded to the blockchain so that any change to a single piece of data is easily identified.
If a single bit was changed in the input to any hash, a completely different sequence of numbers and letters would be created. This principle allows the nodes participating in the blockchain to detect any changes to data. (More on this in the coming weeks!!)
In addition to hashing, blockchain relies on public-key cryptography to acknowledge the idea of ownership on the blockchain. Hashing and public-key cryptography work hand-in-hand to maintain consensus in the system. Through consensus, the entire network has common knowledge of the transactions and any action is recorded and made available for the platform to view. (More on this also in the coming weeks!!)
More on hashing and public-key cryptography next week!!