Blockchain Byte - Week 24 Trees & Roots

Table of Contents
- Recap
- Merkle Tree / Merkle Root
- Application in Blockchains
- Data Immutability
- Transaction Query
- Optimal Space Usage & Transaction Verification
Recap
Last week we explored how blocks are mined in a blockchain - meaning how new transactions are authorized and added to the decentralized ledger.
We also explained Proof of Work which is the solution to the cryptographic puzzle the miners have to solve to add a block to the blockchain. The two fields in the block header related to mining are
a. Target &
b. Nonce
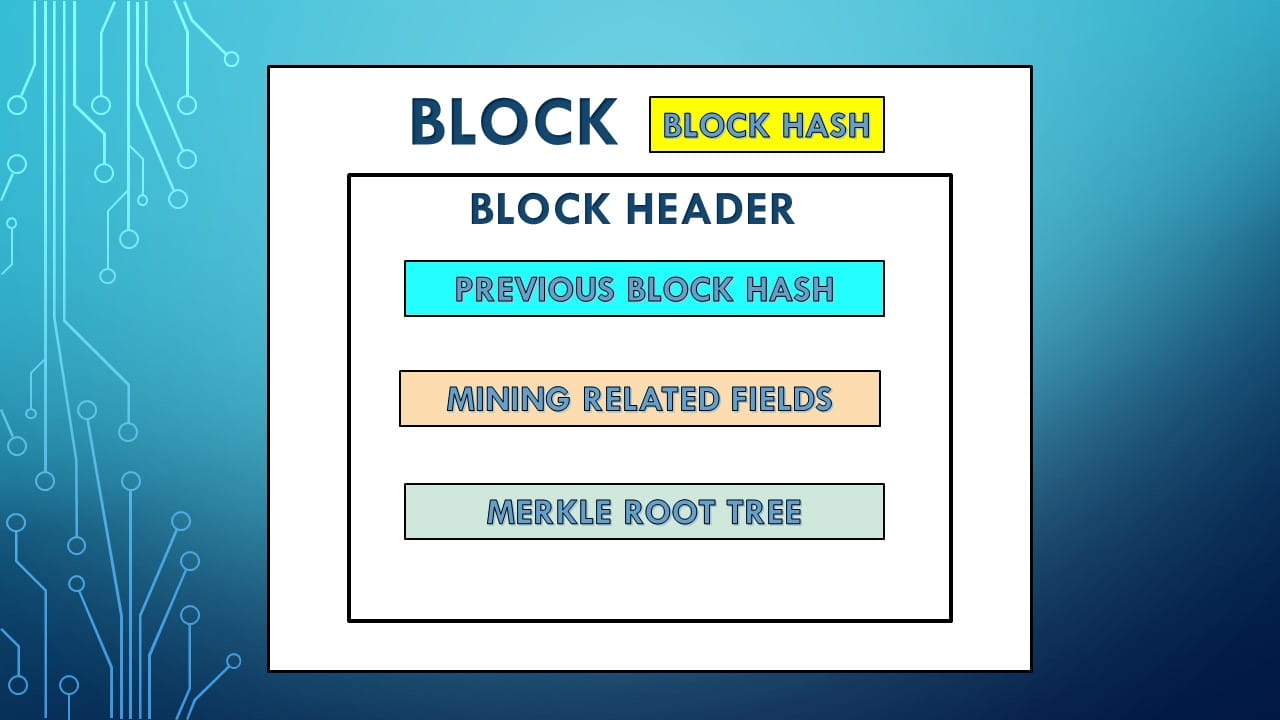
Let us now explain the next field in the Block header - Merkle Tree.
Merkle Tree / Merkle Root
(Before going further, it is recommended to revisit Week 12 & Week 13 related to Hashing & Public Key cryptography).
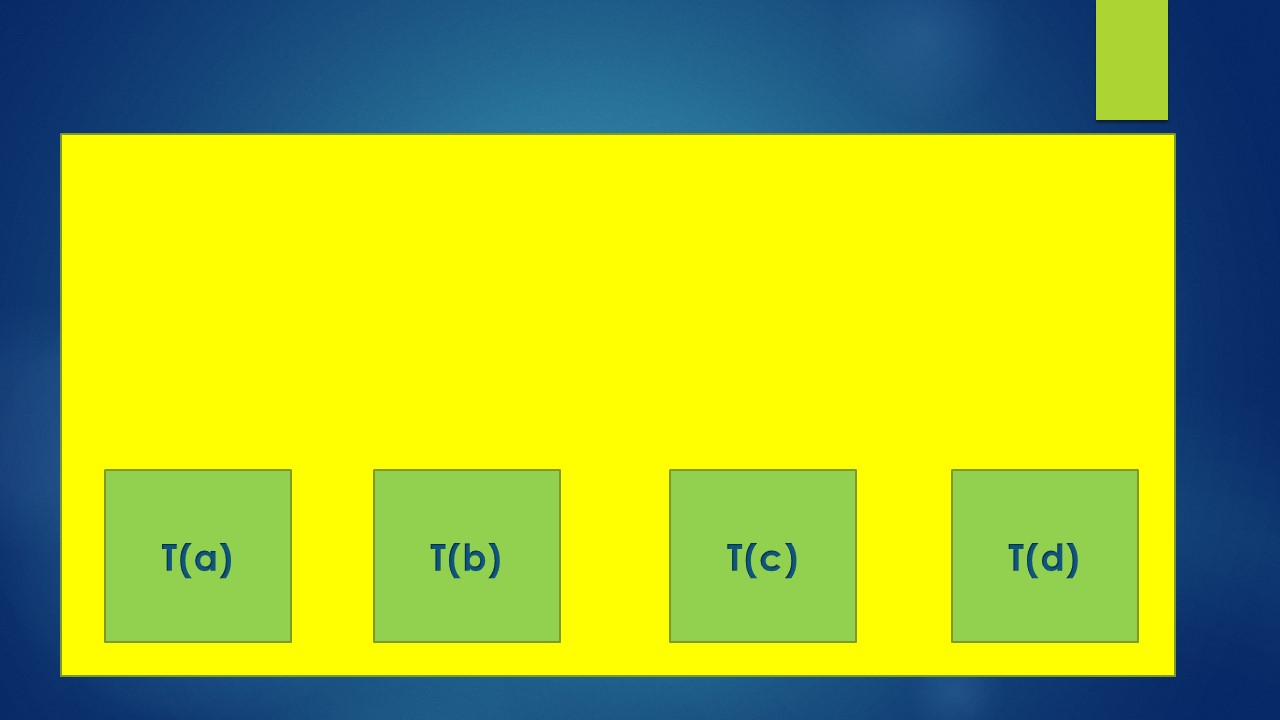
Let us assume there are four transactions in a block as below :
Transaction A - T(a)
Transaction B - T(b)
Transaction C - T(c)
Transaction D - T(d)
Let us visualize these transactions in the block as below:
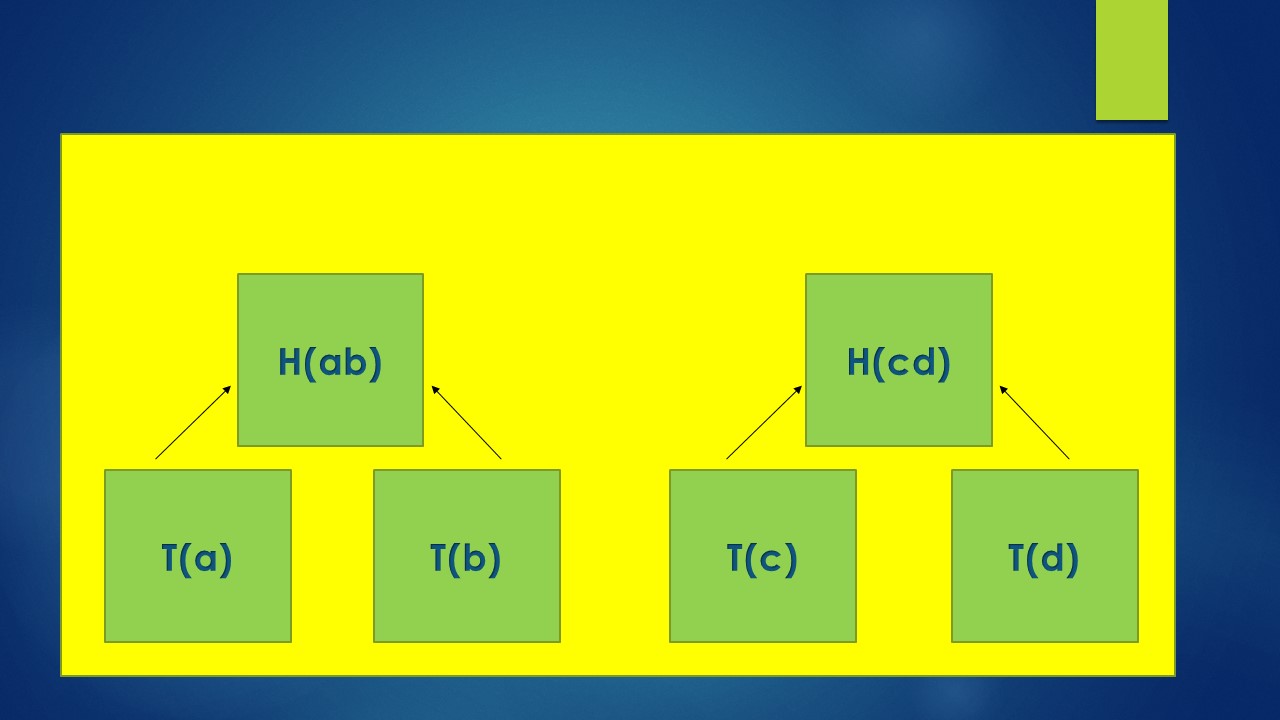
Let us now hash transactions T(a) & T(b) to get a fixed hash output called H(ab). Similarly, we can hash T(c) & T(d) to get hash output H(cd).
These two hash outputs - H(ab) & H(cd) is now propagated to the next level meaning it follows a bottom up logic where the hash values flow from bottom to top.
The below visualization makes it more clear.
Now, let us hash H(ab) & H(cd) to get a fixed hash output called H(abcd). Now this hash value is one level higher than the previous hash outputs.
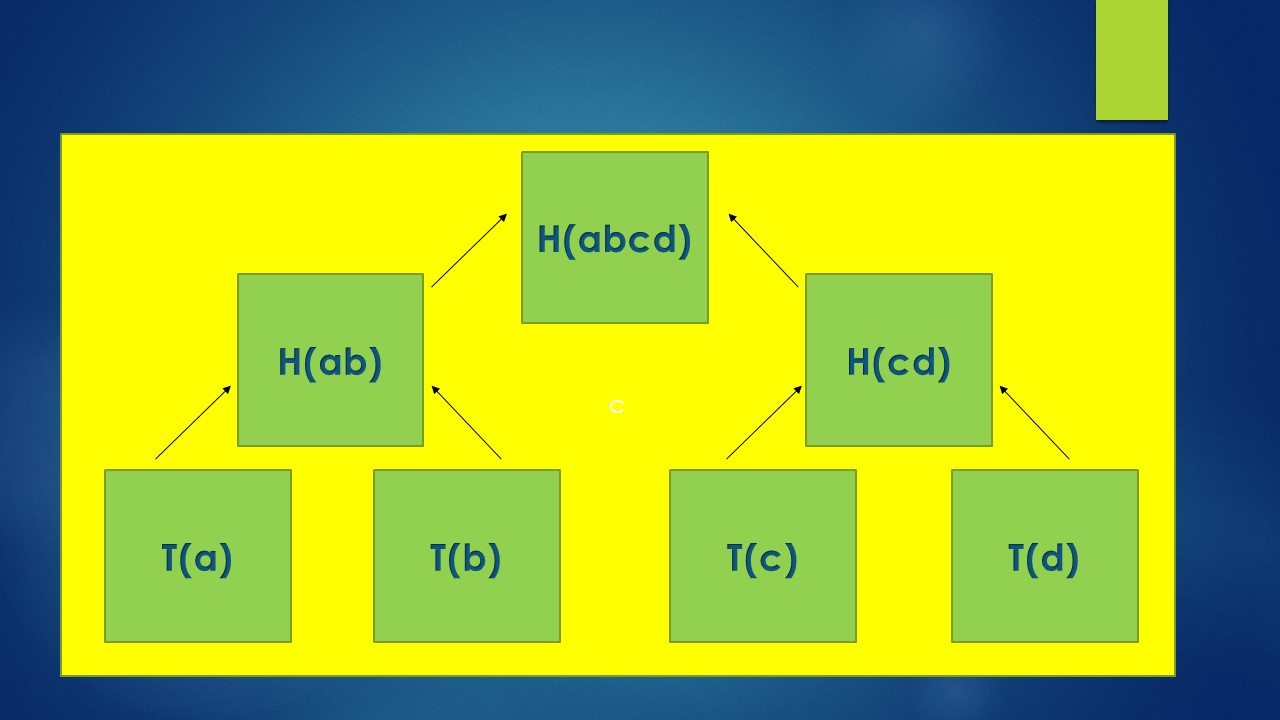
Now, there are no more pairs to hash. This last level of hash output H(abcd) is called a Merkle Root and the total data structure is called a Merkle Tree. It is more like an inverted tree with leaves at the bottom and root at the top.
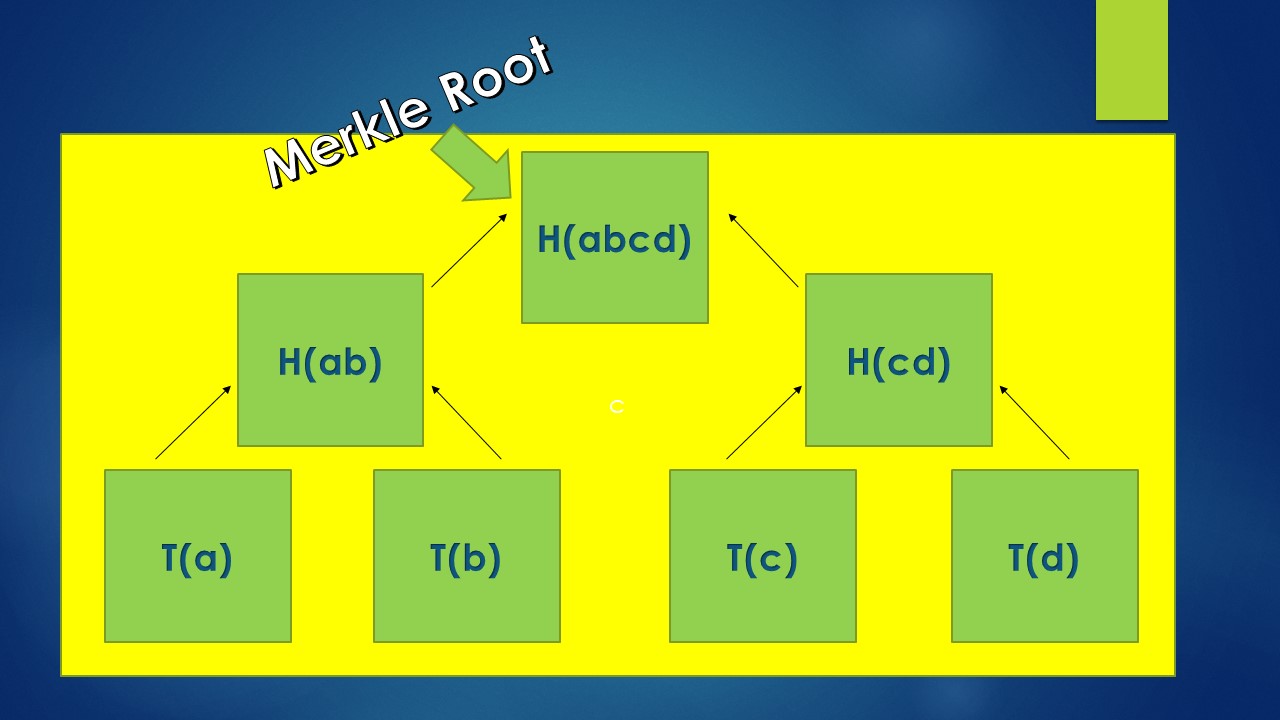
Each member of a tree is called a node.
The bottom nodes of the tree (T(a) to T(d)) are called leaf nodes.
The node which is created out of hashing two nodes is called a parent node [H(ab) or H(cd)] and the nodes being hashed are called child nodes of that parent node.
Now that we know the basic structure of a Merkle tree, why is it used in a blockchain?
We saw above that the Merkle root is created by hashing each pair of nodes from the bottom till it reaches the root. So, the Merkle root is representative of all the data in the Merkle Tree. Thus, it acts as a digital fingerprint of the data set in that tree. In other words,
Merkle Trees are used to summarize all the transactions in a block and provides a very efficient way to identify whether a transaction is included in a block.
Application of Merkle Tree & Root in a Blockchain
Data Immutability
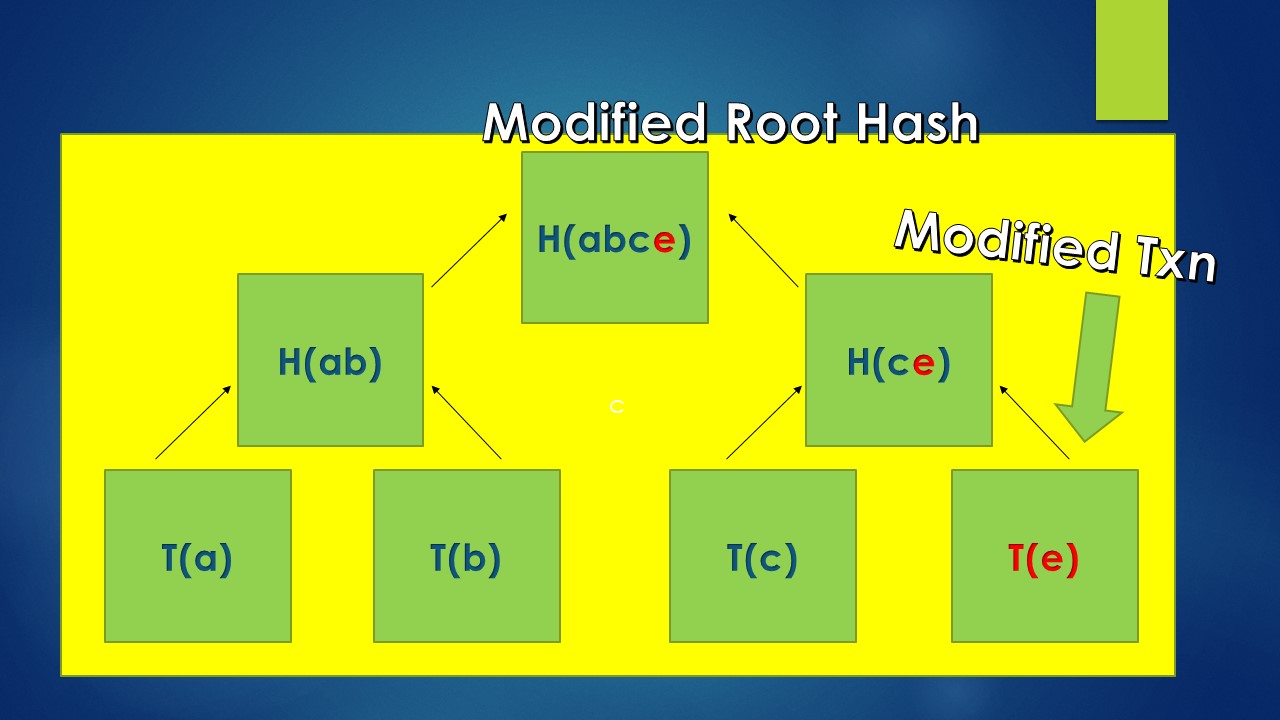
We know that Blockchain is a distributed application where the ledger is replicated and stored by nodes in the network. Each node stores the data in the ledger individually. So, if anyone tries to alter data in any block, the hash of the Merkle root which forms part of the block header also changes and others in the network can detect this based on the mismatch in the root hash.
Even a slight change in the data will change the hash value of the leaf nodes and this will change the hash values of all the nodes above it till the root node, thus changing the root hash.
We know that the Block header includes the previous block hash, the Merkle Root & the mining related fields (Nonce & Target). Adding the Merkle Root ensures that it creates an immutable record of transactions in the block.
Transaction Query
Also, another major use of the Merkle Tree is that it makes the operation of searching for a transaction faster & more efficient. One can easily check whether a particular transaction is included in the tree, without going through the entire tree. It proves that a particular transaction is included in the block.
Optimal Space Usage & Transaction Verification
The original Bitcoin paper gave two examples of use cases for the Merkle Tree :
- Blockchain Pruning &
- Simplified Payment Verification (SPV)
As & when transactions get added to a Blockchain, it becomes larger & larger. The Bitcoin Blockchain size is around 491.5 GB while the Ethereum Blockchain is around 345.17 GB (Source : here).
Blockchain pruning is a way to reduce unwanted space in a Blockchain by pruning (removing) used transactions from a node's local storage with the help of Merkle trees to ensure optimum utilization of a device storage space. This is more applicable to SPV nodes.
We referred to SPV nodes in one of my earlier blogs (Week 11 - Nodes). To recap,
SPV nodes refer to Simplified Payment Verification Nodes. These nodes are designed to run on space & power constrained devices like mobile devices.
For such devices, a Merkle Tree allows them to operate without storing the full blockchain.
To verify a transaction in a block without having to download the full transactions, they can download only the block headers which contain the Merkle root hash which in turn contains the hash of the individual transactions. Then, using the Merkle path, they can ensure that the transaction is included in that block in collaboration with full nodes.
(Full nodes are nodes which contain & store the entire transaction data in the Blockchain)
One question - What if there are odd number of transactions or nodes in a block? In that case, the last transaction or node is duplicated which will be hashed.